
논문 링크: https://arxiv.org/abs/2103.00020
Abstract
- 컴퓨터 비전에서는 일반적으로 시각적 개념을 명확히 하기 위해 추가적인 라벨 데이터가 필요하며, 이는 일반성과 사용성을 제한하는 요인이 되었다.
- Raw 이미지 데이터를 직접 학습시키는 것은 이러한 제한을 극복할 수 있는 대안이 될 수 있다.
- 본 논문에서는 인터넷에서 수집한 4억 개의 이미지와 텍스트 쌍 데이터셋을 사용하여 처음부터 최신 상태의 이미지 표현을 학습하고, 각 이미지에 어울리는 캡션을 예측할 수 있는 기술을 개발했다.
- 30개 이상의 다양한 데이터셋으로 벤치마킹을 실시하였으며, 완전 지도 학습 모델과도 경쟁할 수 있는 수준의 성능을 보여주었다.
Introduction and Motivationg Work
- Web-scale의 거대한 데이터로 학습한 GPT3 같은 text-to-text 모델은 제로샷 변환이 가능하다.
- 비전 분야에서는 ImageNet처럼 비교적 작은 크기의 데이터만 있어서, web text를 직접 사용하는 연구가 진행되었다.
- VirTex, ICMLM, ConVIRT는 text를 사용해 image를 표현하는 최신 방법들이다.
- 이들은 transformer 기반 언어 모델링, masked language modeling, contrastive objective learning 기술을 사용한다.
- 여러 연구들은 제한된 양의 supervised "gold label" 데이터와 무제한의 raw text를 사용하는 사이에서 실용적인 중간 방법을 찾았다.
- 하지만 기존 방법들은 고정된 softmax classifier를 사용해 dynamic output이 부족했으며, 제로샷 능력에서 유연성이 부족한 한계를 가졌다.
- 이 논문에서는 인터넷의 공개된 데이터를 활용해 400M 데이터셋을 만들고, ConVIRT의 간단한 버전을 scratch부터 학습시킨 CLIP (Contrastive Language-Image Pre-training) 방법을 소개한다.
- CLIP은 30개 이상의 다른 데이터셋으로 벤치마킹을 진행했으며, 그 결과 완전 지도 학습 기준과도 경쟁할 만한 성능을 보였다.
Approach
Natural Language Supervision
- 자연어를 포함한 supervision으로 학습하는 개념은 이전부터 있었으나 다양한 이름으로 불려왔다.
- 이제 이러한 접근들을 "natural language supervision"으로 통칭한다.
- 이 방법의 장점은 라벨 데이터보다 데이터 크기를 확장하기 쉽고, flexible zero-shot transfer에 더 적합하다는 것이다.
Creating a Sufficiently Large Dataset
- 인터넷에서 접근 가능한 공개형 대규모 데이터들이 natural language supervision의 주요 동기이다.
- 기존 데이터들은 사용한 연구 결과를 볼 때 아직 부족하다고 판단되어, 새로운 400M 이미지와 텍스트 쌍 데이터셋을 인터넷에서 구축했다.
- 이 데이터셋은 500,000개의 쿼리를 통해, 쿼리 당 최대 20,000개의 결과를 반영하여 WIT(WebImageText)라고 명명했다.
Selecting an Efficiaent Pre-Training Method
- 기존의 vision 연구들은 이미지넷의 1000개 클래스로 학습했음에도 불구하고 많은 리소스를 필요로 했다.
- 이번 연구에서는 더 큰 데이터셋을 사용하므로 더 효율적인 학습 방법이 필요했고, 특정 클래스로 구분되지 않기 때문에 cross-entropy loss와 softmax를 사용할 수 없었다.
- 따라서 contrastive learning을 선택했으며, 기존 방식과 달리 텍스트의 순서를 고려하지 않고 예측할 수 있도록 bag-of-words encoding을 활용해 학습을 진행했다.
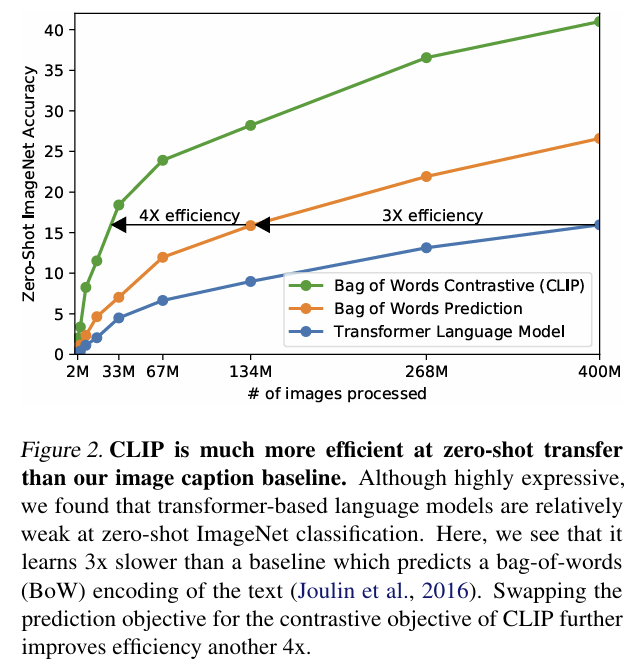
- 이를 통해 figure2에서 볼 수 있듯이 효율적인 학습이 가능했다.
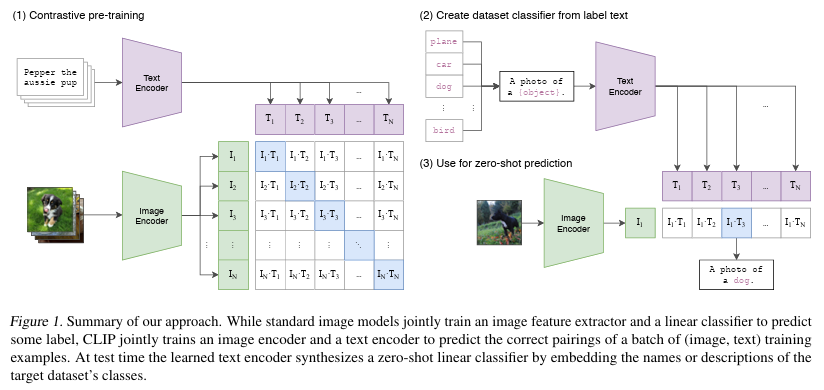
- Contrastive learning은 positive pair를 서로 가깝게, negative pair는 멀어지도록 학습하는 방식으로, 라벨 정보가 없어도 특정 기준만 있으면 positive인지 판단할 수 있어 자기지도 학습에 효과적이다.
- 학습은 배치 단위로 이루어지며, 배치 사이즈가 n일 때 n개의 (image, text) 페어가 생성되고, 이 중 n개는 positive pair, 나머지 n(n-1)개는 negative pair로 구성된다.
- 텍스트와 이미지는 각각 Text Encoder와 Image Encoder를 통해 벡터 값으로 변환되며, 이들의 cosine similarity를 계산하여 서로의 거리를 조절한다.
- Positive pair는 cosine similarity를 작게 하고, negative pair는 크게 하여 학습을 최적화하며, 최종적으로는 Cross Entropy Loss를 사용해 Cross-modality 학습을 진행한다.

- pseudocode는 위와 같다.
Choosing and Scaling a Model
- 모델 선택과 확장 과정에서, 텍스트 인코더로는 약간 수정된 Transformer를 사용했고, 이미지 인코더로는 ResNet과 ViT(Vision Transformer) 버전을 도입했다.
- 과거 컴퓨터 비전 연구에서는 모델의 너비나 깊이 중 하나만 확장하는 경향이 있었지만, 이번 연구에서는 ResNet 이미지 인코더의 너비, 깊이, 해상도를 모두 확장하여 성능을 향상시켰다.
- Text Encoder는 ResNet의 너비에 맞추었으나 깊이는 증가시키지 않았는데, 이는 CLIP 성능에 큰 영향을 주지 않았기 때문이다.
Training
- 학습 과정에서는 다양한 크기의 ResNet 모델과 ViT 모델이 사용되었다.
- 특히 ResNet에서는 전통적인 Global Average Pooling 대신 Attention Pooling을 사용했으며, ViT 모델 중에서는 ViT-L/14가 가장 좋은 성능을 보여 모든 실험의 주요 backbone으로 선택되었다.
- 학습에는 매우 큰 minibatch 크기인 32,768과 32개의 epoch가 사용되었으며, 메모리와 시간을 절약하기 위한 많은 노력(예: mixed precision)이 포함되었다.
- 가장 큰 ResNet 모델인 RN50x64는 592대의 NVIDIA V100 GPU를 사용하여 18일 동안 학습했으며, 가장 큰 ViT 모델 학습에는 256대의 V100 GPU를 사용해 12일이 소요되었다.
Experiments
Zero-Shot Transfer
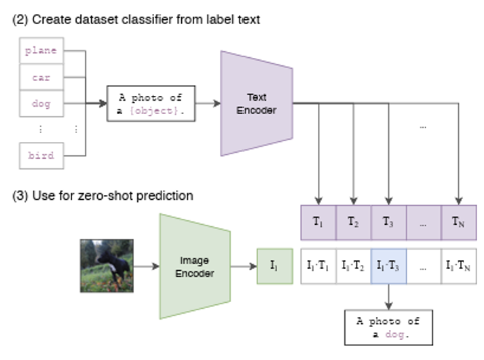
- 사전학습된 CLIP을 파인튜닝 없이 그대로 사용하는 것을 의미
- 예를 들어 CIFAR10 이미지에 CLIP을 적용하고 싶으면, 이미지를 그대로 이미지 인코더에 넣고 CIFAR10의 10개 클래스 라벨에 대한 텍스트 표현을 추출한다.
- 그다음 이들 사이의 cosine similarity를 계산해서 가장 높은 값을 보이는 클래스를 예측 결과로 선택한다.
- 이와 같이 training data를 사용하지 않고도 predict이 가능해서 zero-shot
- Zero-shot prediction은 학습과 거의 유사하다.
- 이미지와 텍스트 각각을 해당 인코더에 넣어 feature vector를 얻고, 입력 이미지에 대해 각 클래스와의 similarity를 계산한다.
- 이 중 가장 높은 similarity를 보이는 클래스를 정답으로 선택한다.
- 이 때, text feature의 수는 총 class의 개수와 같다.
- 초록색이 image feature
- 사용하는 클래스의 수가 N개라면, 각 클래스를 설명하는 문장을 생성한다.
- 이 문장들을 text encoder를 통해 feature로 변환하고, 이미지 feature와 매칭시켜 각각의 cosine similarity를 계산한다. 이 중 가장 높은 값을 보이는 클래스를 예측 결과로 선택한다.
- 이러한 방식을 통해 CLIP은 고정되지 않은 개수의 클래스에 대해 예측할 수 있으며, 이는 전통적인 라벨을 사용하는 대신 이미지와 자연어 사이의 alignment를 학습하는 것을 기반으로 한다.
- Motivation
- 원래 특정 카테고리 내에서만 unseen data에 대해 적용되었지만, 이 연구에서는 그 개념을 확장하여 unseen dataset에서의 classification을 제로샷으로 정의한다.
- 이전에는 unsupervised learning에 초점을 맞춘 representation learning에 집중했던 반면, 이 논문은 제로샷 transfer를 통해 task-learning 능력을 측정하는 것으로 접근한다.
- Initial Comparision to Visual N-grams

- Image classification에서 zero-shot transfer를 처음 사용한 연구는 Visual N-Grams이다.
- 이 연구에서 비교 대상이 Visual N-Grams밖에 없었고, 성능 비교의 주 목적이 아니었다고 논문은 주장한다.
- CLIP은 Visual N-Grams 방식보다 사용된 데이터가 기존보다 10배 많고, 예측과 훈련에 각각 100배, 1000배의 컴퓨팅 파워가 소모되었으며, Transformer 같은 새로운 아키텍처가 도입되었다는 점을 강조하고 있다.
- Prompt Engineering and Ensembling
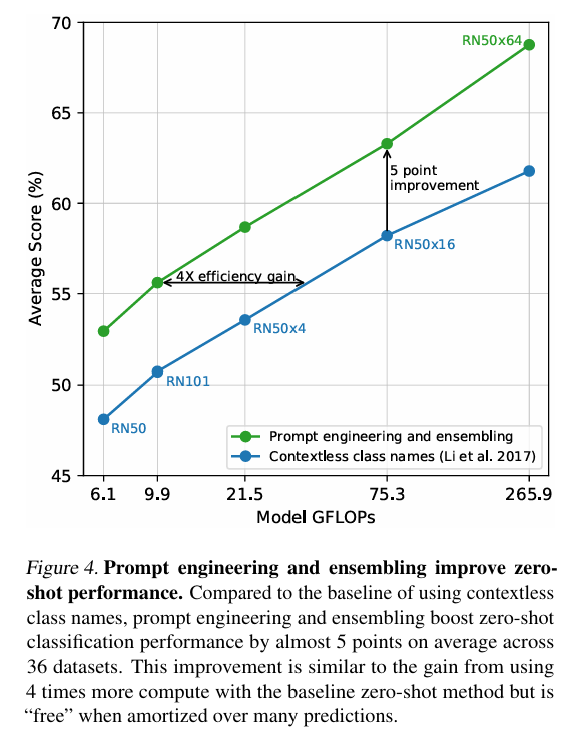
- 단어를 그대로 사용할 때 동음이의어 문제가 발생할 수 있고, 데이터 자체가 문장 형태로 학습되었다.
- 따라서 단순한 단어보다는 "A photo of a {label}"와 같은 문맥을 살린 프롬프트 템플릿 사용이 성능에 좋았다.
- "A photo of a big {label}", "A photo of a small {label}" 같은 다양한 문맥을 사용한 프롬프트를 앙상블로 활용하면 성능이 더 향상되었으며, GPT처럼 프롬프트 엔지니어링과 앙상블 사용으로 약 5점의 성능 향상이 있었다.
- Analysis of Zero-shot CLIP Performence

- Linear probe는 학습이 완료된 encoder를 가져와서 지도학습으로 classifier만 다시 학습하는 방법이다.
- 이 방법의 전제는 encoder가 이미 좋은 표현을 학습했다면, 단순히 classifier만 조정해도 높은 성능을 낼 수 있다는 것이다.
- 제로샷 CLIP은 복잡한 task에서 성능이 다소 떨어질 수 있지만, 라벨 데이터 없이도 라벨 데이터를 사용하여 학습한 모델들과 비교했을 때 비슷하거나 더 좋은 성능을 보인다.
- 이는 CLIP이 라벨 데이터 없이도 효과적인 학습 결과를 보여줄 수 있음을 의미한다.
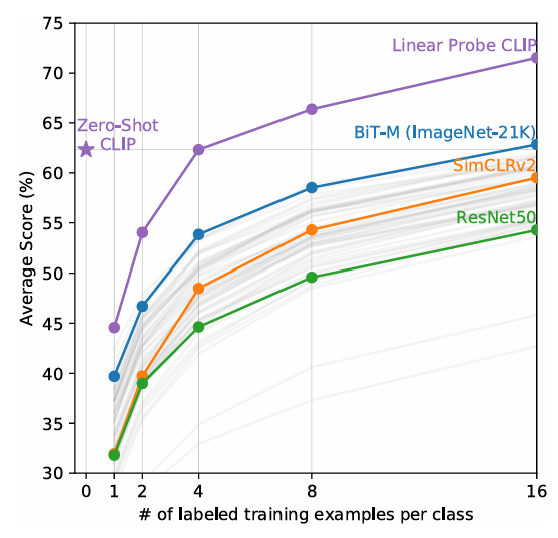
- LIP 모델을 지도학습한 모델들과 비교했을 때, CLIP의 성능이 좋지 않다고 보기 어렵기 때문에 zero-shot CLIP을 few-shot 모델들과 비교한다.
- CLIP은 일부 few-shot 시나리오보다 zero-shot에서 더 좋은 성능을 보였다.
- Zero-shot에 linear layer를 추가하여 학습할 때, x축은 클래스당 학습 이미지의 수인 N-Shot, y축은 Average Score로 설정했다.
- 그 결과 zero-shot의 성능이 4-shot과 동일하게 나타났다.
- 논문에서는 one-shot이 zero-shot보다 성능이 높을 것으로 예상했으나, 실제로는 낮은 결과가 나타났다.
- 이는 CLIP 모델이 자체적으로 잘 분류할 수 있음에도 불구하고, linear layer를 scratch부터 학습하면서 각 클래스당 예제가 부족해져 성능이 낮아진 것으로 분석된다.
- 그래도 샘플 수가 증가할수록 예측 성능은 향상된다.
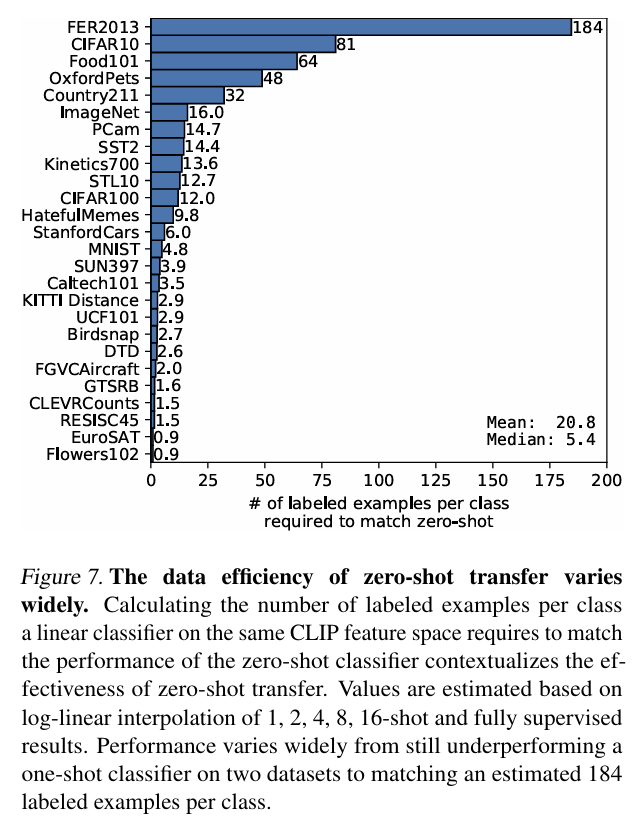
- ogistic regression classifier가 학습해야 할 example의 수에 따라 zero-shot CLIP을 어느 정도 따라잡을 수 있는지 보여주는 그래프이다.
- 데이터셋마다 얼마나 많은 few-shot이 zero-shot과 성능이 일치하는지 보여준다.
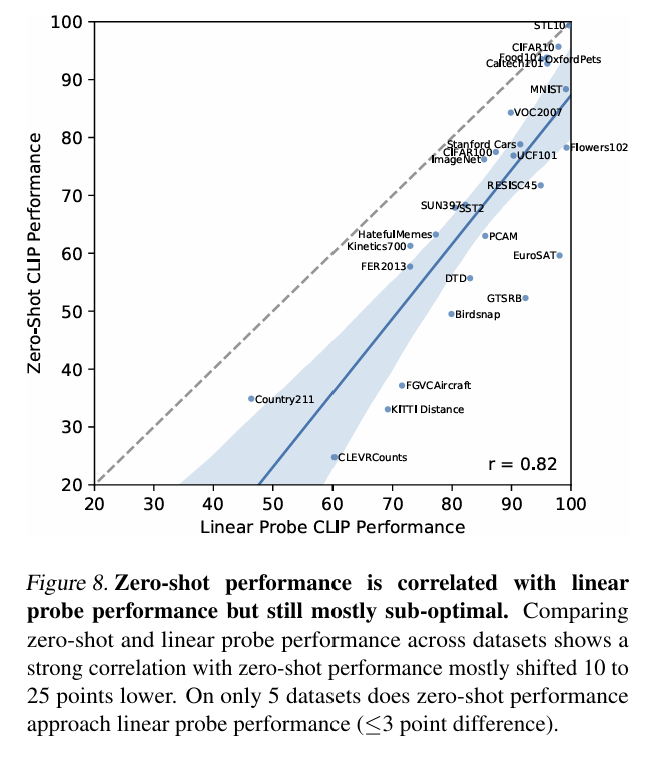
- CLIP 모델을 사용하여 zero-shot 성능과 linear probing 성능을 비교한 그래프에서 y=x 그래프는 이상적인 zero-shot classifier 성능을 나타낸다.
- 같은 사전학습을 한 모델에서는 linear probing의 성능이 더 우수한 모습을 보였지만, 몇몇 데이터셋에서는 zero-shot 성능과 linear probing 성능이 거의 유사했다.
- 이는 CLIP의 zero-shot 예측 능력이 강력함을 보여주지만, 아직 개선할 여지가 있다는 것을 의미한다.
Representation Learning
- Downstream tasks에서는 결국 feature 추출 능력이 중요하다.
- CLIP은 image representation을 잘 추출한다고 알려져 있지만, 이전과 같은 zero shot prediction 성능으로는 모델이 얼마나 좋은 표현을 학습했는지 확인하기 어렵다.
- 일반적으로는 fine-tuning 성능과 linear probing 성능을 비교하여 학습된 표현력을 평가하기 때문에, zero-shot 성능만으로는 CLIP이 우수한 표현을 학습했다고 단정 지을 수 없다.
- 그래서 CLIP의 linear probing 성능 비교 실험을 진행했다.
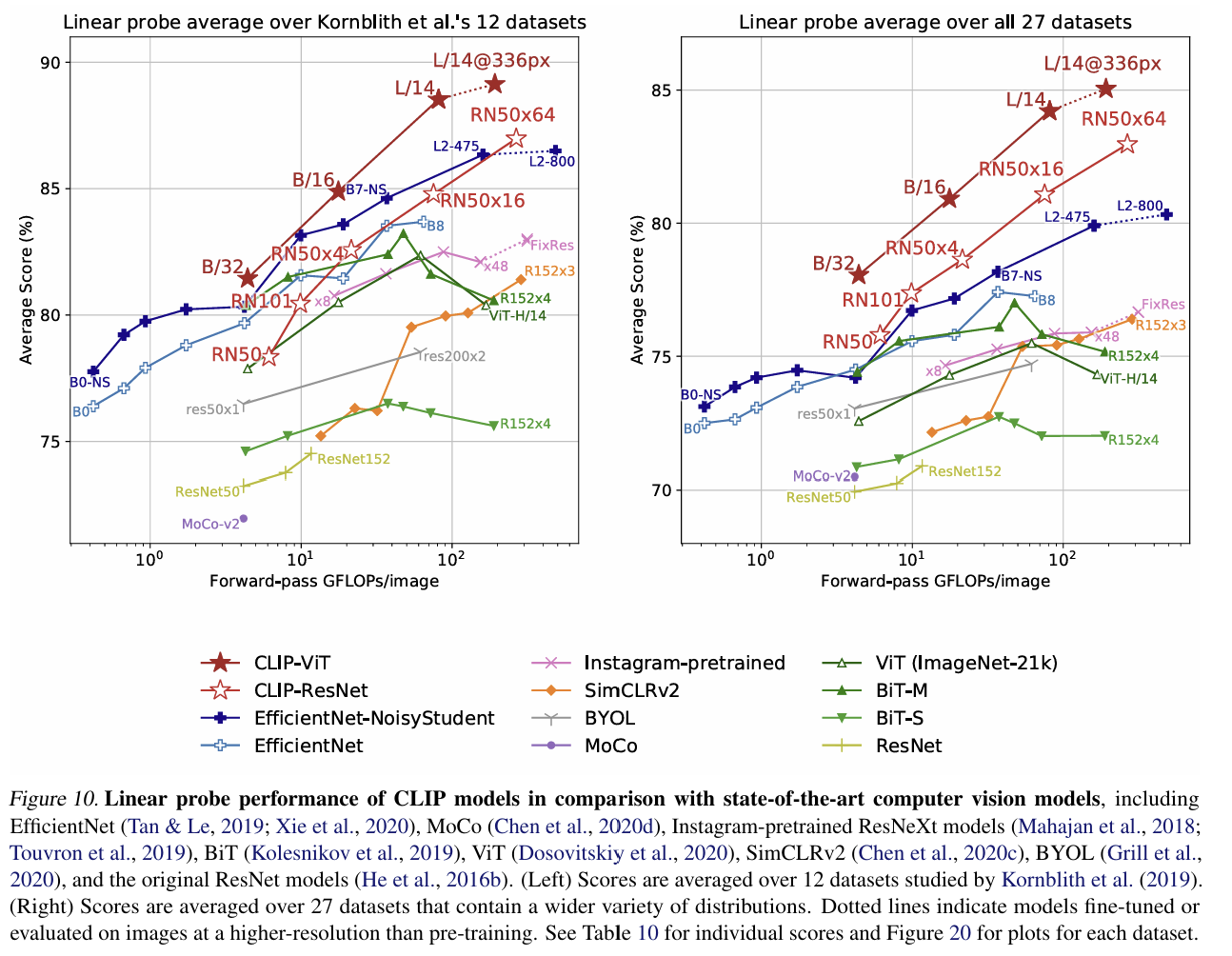
- 다양한 데이터셋과 모델을 대상으로 한 linear probing 성능을 비교한 결과, 모든 크기에서 CLIP 방식으로 학습한 모델의 linear probing 성능이 가장 뛰어났다.
- 이는 image-text 쌍을 contrastive learning으로 학습하는 방법의 우수성을 보여준다
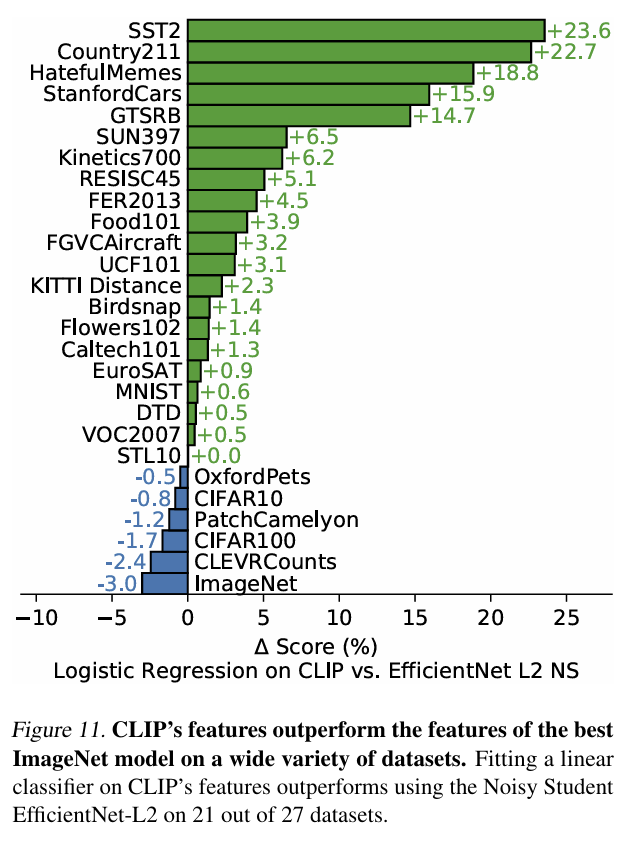
Robustness to Natural Distribution Shift
- Vision model들은 일반적으로 robustness가 떨어지는 경향이 있다.
- 예를 들어, 학습한 데이터셋에 노이즈가 섞이거나 텍스쳐가 변할 경우 성능이 크게 하락하는데, 이는 모델이 학습 데이터를 외우는 형태로 overfitting 되었기 때문이다.
- 이러한 문제는 training set과 test set의 distribution이 동일하다는 가정 하에 발생한다.
- 이 문제를 해결하는 방법 중 하나는 데이터의 domain에 불변하는 특성을 추출하는 것이며, 이를 domain generalization이라고 한다.
- CLIP은 distribution shift에 강한 robustness를 보여준다.
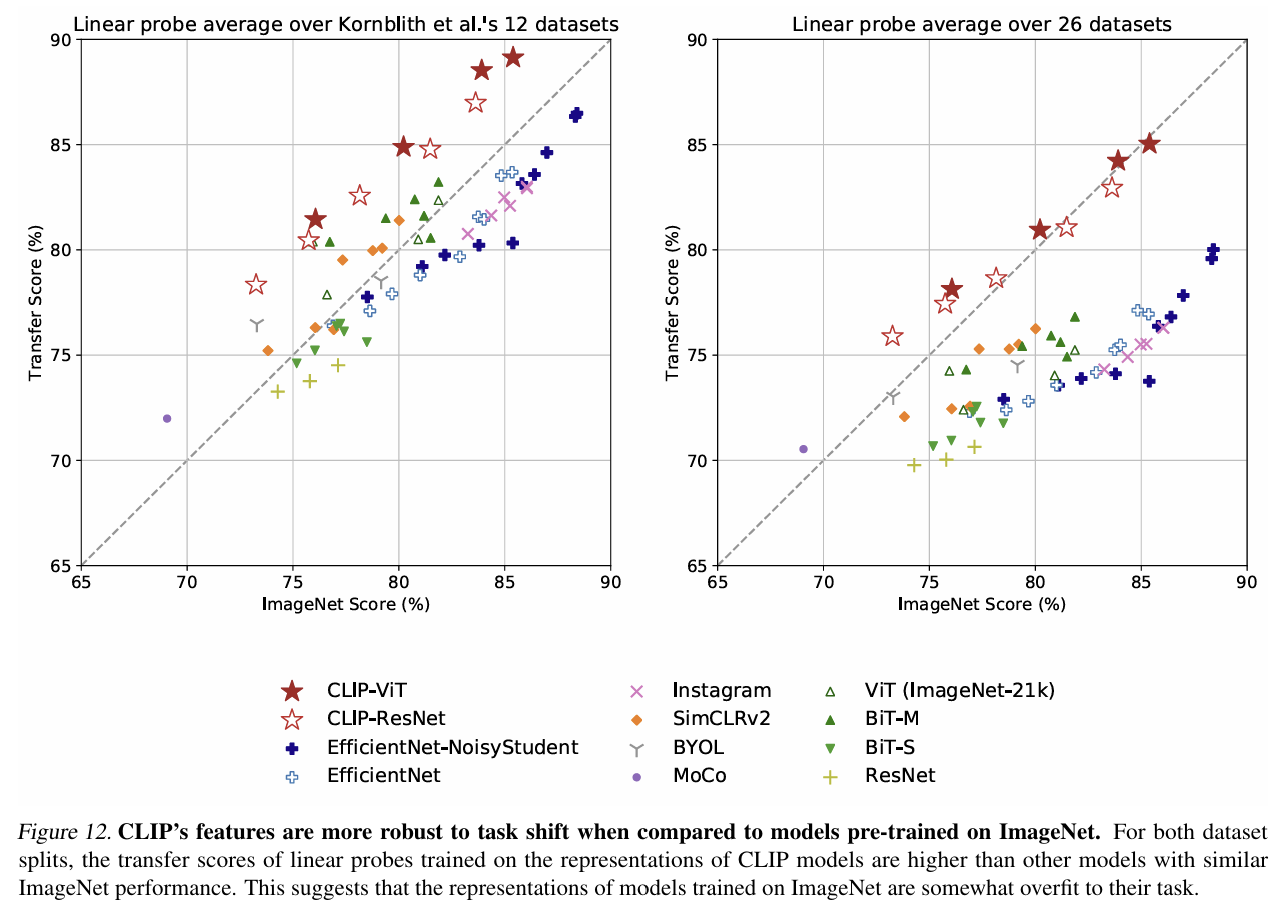
- 다른 task로의 transfer 성능을 평가할 때 CLIP의 representation이 얼마나 우수한지를 보여준다.
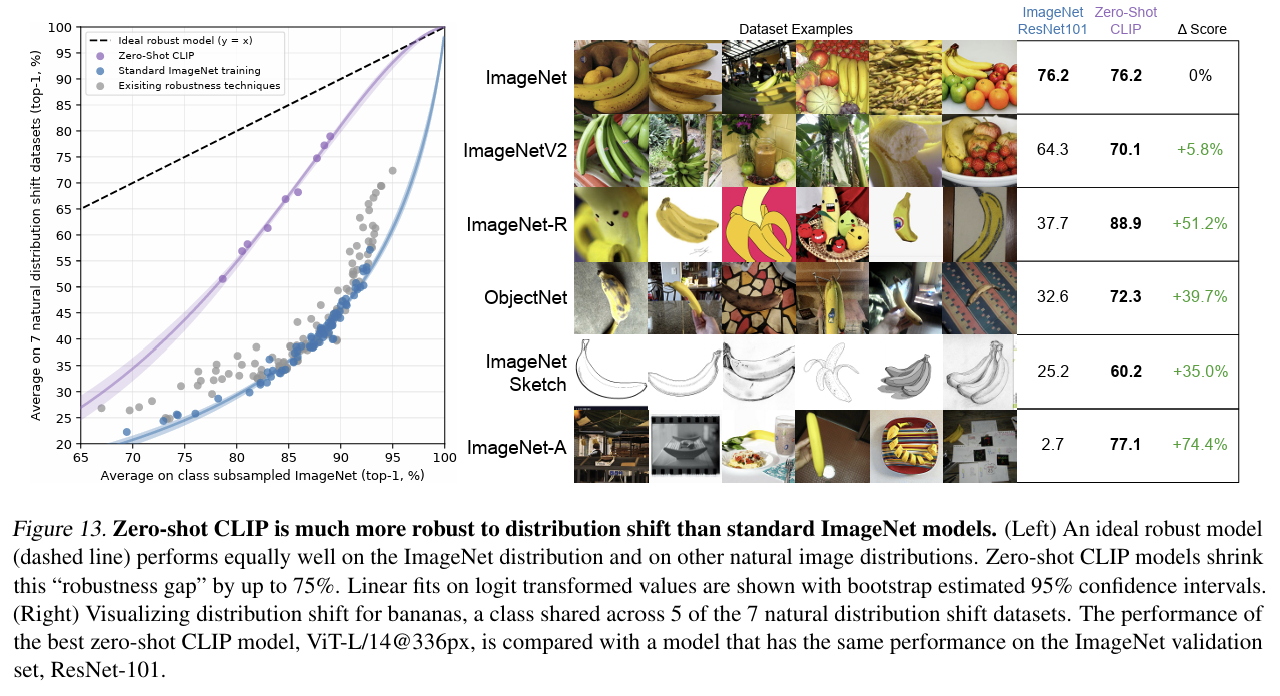
- 다양한 데이터셋에서 모두 기존의 ResNet보다 CLIP의 zero-shot 성능이 더 우수했다.
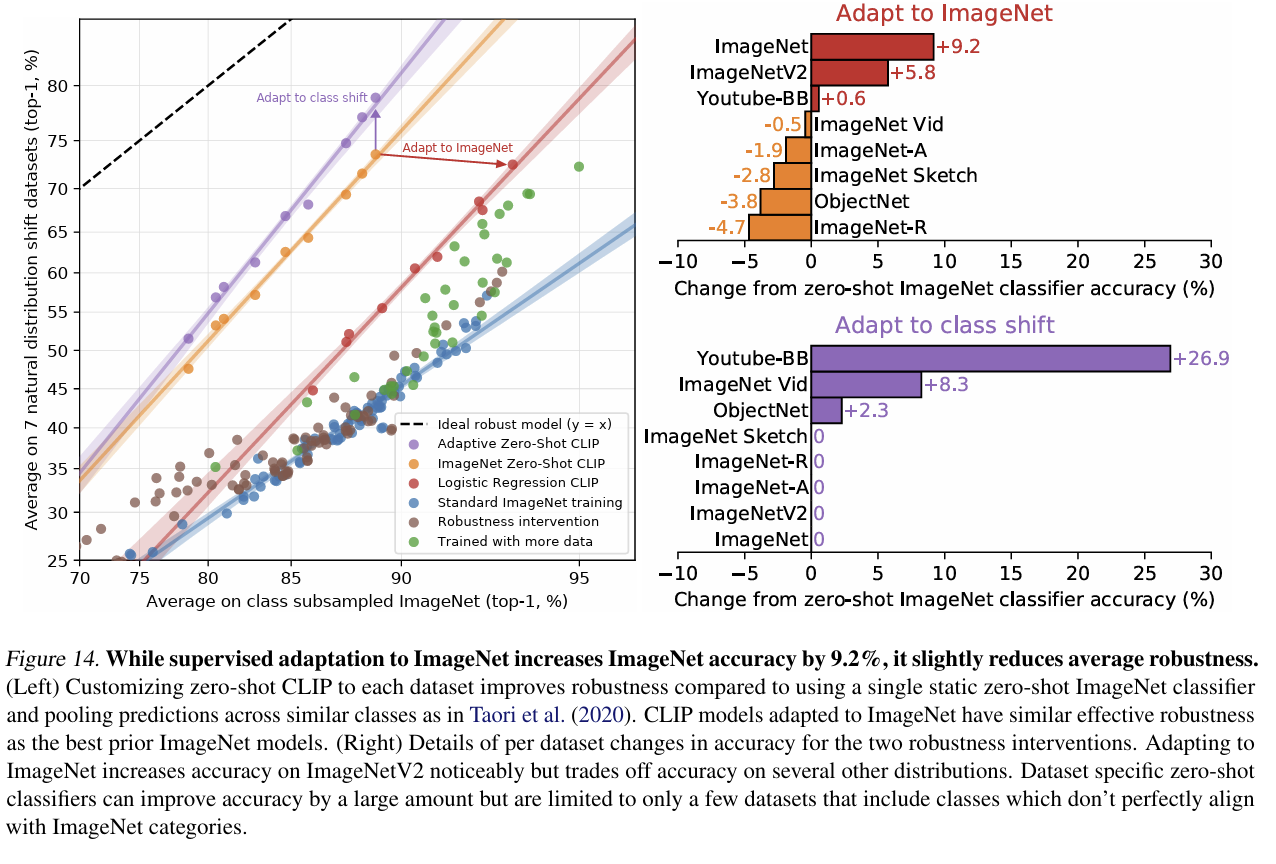
- 또한, ImageNet data로 adapt할수록 정확도는 높아지지만 robustness는 떨어지는 trade-off가 관찰된다.

- Shot 수가 증가할수록 해당 task에 대한 성능은 향상되지만, zero-shot CLIP에 비해 모델의 generality가 감소한다.
Comparison to Human Performance
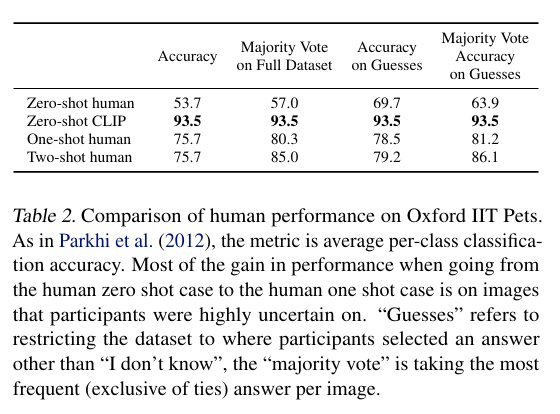
- 사람과 CLIP의 zero-shot, one-shot, two-shot 성능을 비교한 결과, CLIP이 어려워하는 애완동물 종류 구분에서 사람도 어려움을 겪는다.
- 사람은 하나의 샘플만 봐도 정확도가 크게 향상되며, 이는 인간이 자신이 무엇을 알고 무엇을 모르는지 인식하고 있다는 것을 나타낸다. 반면, CLIP은 이러한 메타인지 능력이 부족함을 볼 수 있다.

- 인간은 zero-shot에 비해 one-shot과 two-shot에서 훨씬 더 높은 정확도를 보이지만, CLIP은 zero-shot이 few-shot보다 더 뛰어난 성능을 보인다는 것을 확인할 수 있다.
Data Overlap Analysis
- 인터넷에서 가져온 거대한 데이터셋과 평가 데이터셋이 중복될 가능성이 있지만, 이를 하나하나 검수하는 것은 실질적으로 어렵다.
- 따라서 duplicate detector를 사용하여 유사도가 특정 값 이상인 경우 overlap 집합에 포함시키고, 그 이하라면 clean 집합에 포함시켜 all과 clean을 metric으로 사용하여 데이터셋의 중복 정도를 분석한다.
- 대부분의 경우 overlap 양이 적어, clean에 대한 정확도를 귀무 가설로 설정하고, overlap 부분 집합에 대한 성능 차이를 분석한다.
-
- 일부 데이터에서는 data overlap으로 인해 정확도가 조금 부풀려진 것으로 확인되었다.
- 왼쪽 그림에서는 총 35개의 데이터셋 중 5개만이 신뢰구간을 벗어나며, 그 중 2개는 성능이 더 낮았다.
- 오른쪽 그림은 detector로 탐지한 overlapping example의 비율이 한 자리 수로, overlap에 의한 전체 테스트 정확도의 향상이 크지 않음을 의미한다. 6개의 데이터셋에서만 유의미한 차이가 있었다.

Limitations
- Zero-shot CLIP은 ResNet-50이나 101과 비교해서는 좋지만, SOTA보다 성능이 떨어진다.
- CLIP은 task-specific, fine-grained classification (자동차, 꽃, 비행선 구별), abstract/systematic task (개체 개수 세기), novel task (사진 상에서 가장 가까운 차까지의 거리 분류) 등에서 성능이 떨어진다.
- 이는 zero-shot CLIP이 강한 부분도 있지만 그렇지 못한 부분도 많다는 것을 의미한다.
- Task-specific 모델과 비교했을 때 세분화된 분류 문제에서 특히 약하다.
- 또한, 사진에서 가장 가까운 자동차까지의 거리를 분류하는 task와 같은 CLIP이 사전학습 단계에서 학습하지 않았을 새로운 종류의 문제에서는 거의 맞추기 어려운 수준일 수 있다.
- Deep learning의 데이터 활용률이 매우 낮은 것도 별로 개선하지 못했다.
- 4억 개의 이미지를 1초에 하나씩 32 epoch을 수행하면 405년이 걸린다.
- Rendered SST2라는 OCR 데이터를 학습했는데, MNIST를 봤을 때 CLIP은 단순한 logistic regression 지도 학습보다 떨어지는 성능을 보였다.
- 이는 CLIP이 일반적인 deep learning 모델의 취약한 일반화(generalization) 문제를 거의 해결하지 못했다는 것을 의미한다. 인터넷 데이터를 필터링 없이 그대로 학습하므로 social bias가 있을 수 있다.
Broader Impacts
- CLIP은 다양한 작업을 수행할 수 있고, 광범위한 기능을 가질 수 있다.
- 예를 들어, 고양이와 개의 이미지를 주고 분류를 시킬 수도 있고, 백화점에서 찍은 이미지를 주고 좀도둑을 분류하도록 요청할 수도 있다.
- CLIP은 OCR을 수행할 수 있으므로, 스캔한 문서를 검색가능하게 만들거나, 화면을 읽거나, 번호판을 인식할 수 있다.
- 이러한 기능은 동작 인식, 물체 분류, 얼굴 감정 인식 등 광범위한 응용이 가능하므로 감시용으로 사용될 수 있다.
Bias
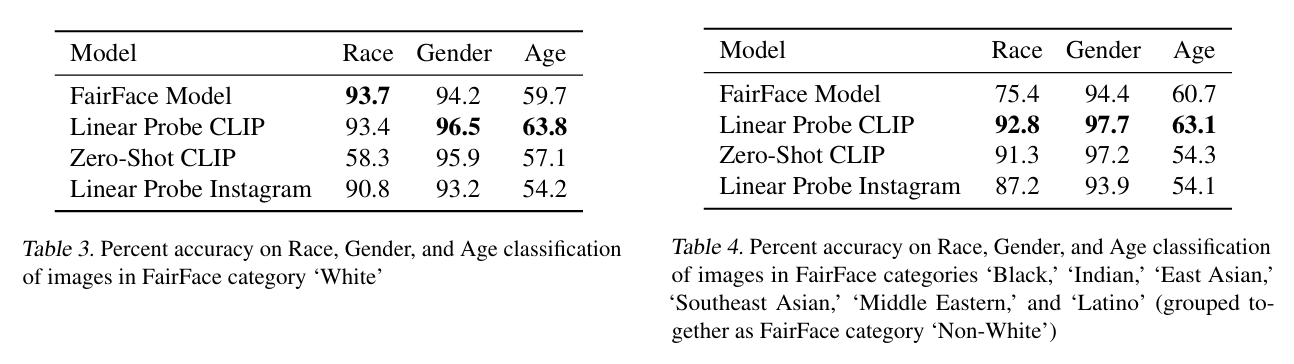
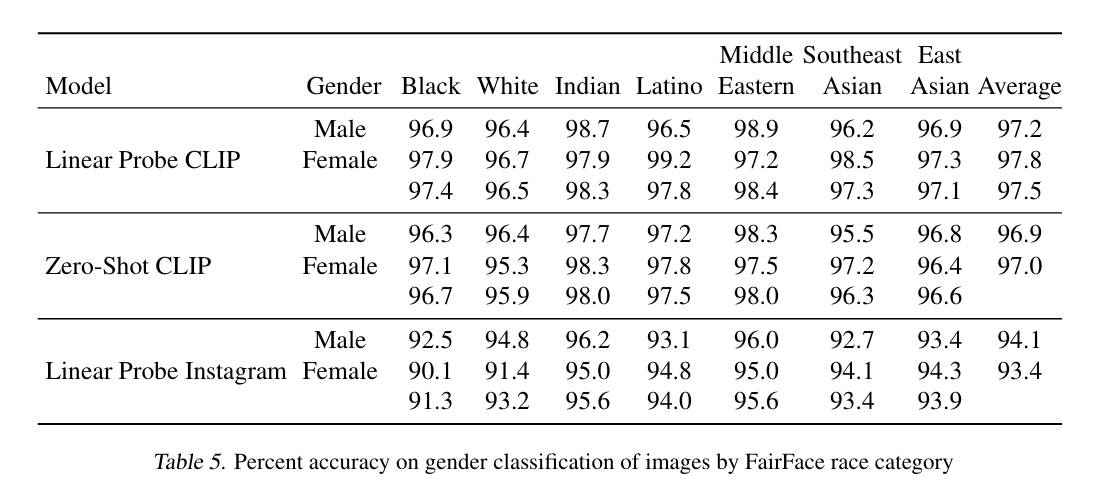
- 사회적 편견은 데이터셋에 그대로 녹아들어가고, 이를 통해 학습하는 모델도 이를 그대로 학습할 수 있다.
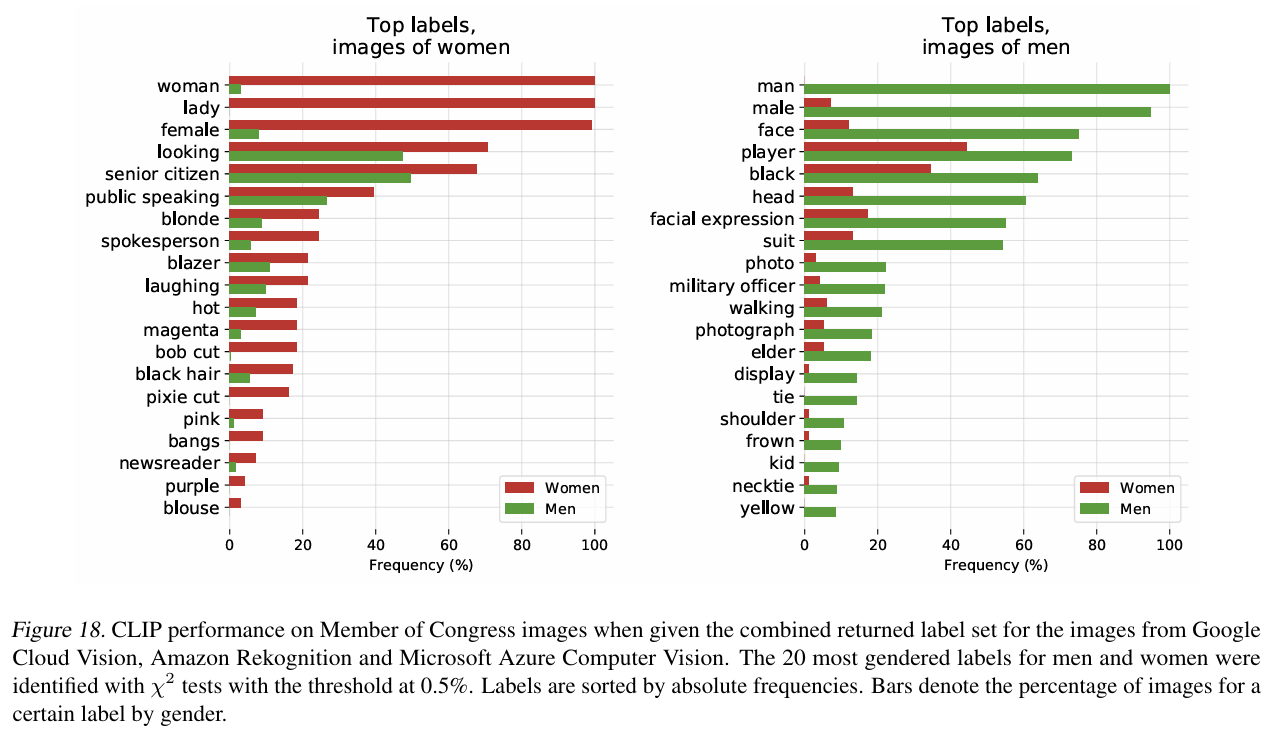
- 실제로, 이 논문에서는 FairFace benchmark dataset으로 여러 실험을 진행했다.
- FairFace dataset은 기존의 face dataset에서 백인의 비율을 줄이고 성별과 인종이 고루 분포하도록 수집된 데이터셋이다.


Future Work
- 연구 초기 단계에서 모델의 잠재적인 downstream task들을 고려하고 그 응용 가능성에 대해 심도 있게 탐구한다.
- 상당한 민감도를 지닌 작업에 대해 정책 입안자의 개입이 필요함을 인식하고, 이러한 작업들을 명확히 밝힌다.
- 모델의 편향을 보다 정확하게 특성화하고, 이를 통해 다른 연구자들이 관심을 가질 수 있는 영역 및 필요한 개입 사항들에 대해 경고하는 작업을 수행한다.
- 잠재적인 실패 모드와 그 영역들을 식별하여, 이를 기반으로 추후 연구의 방향을 설정한다.
Related Work
- CLIP은 image, text의 multimodal embedding space를 학습했으며, 이는 vision+language의 많은 분야에 활용될 수 있다.
- 이에는 image-text pair dataset, Text-Image Retrieval, weakly supervised learning, learning joint (vision + language) model 등이 포함된다.
Conclusion
- 자연어처리에서 크게 성공한 task-agnostic web-scale 사전학습 방식을 vision 분야에도 적용했다.
- 모델의 성능, 사회적인 의미 등을 분석했으며, CLIP은 다양한 task에 대해 사전학습을 했고, 자연어 prompt를 통해 많은 데이터셋에 대하여 zero-shot transfer를 가능하게 했다.
- 성능 향상이 필요하지만 task-specific한 모델들과 비교해도 크게 밀리지 않는다.